
The Machine Learning Process
Introduction
To build industry level solutions every Software solution follows a process. For software development it’s called Software Development Life Cycle(SDLC) and for Machine Learning it’s called Machine Learning Life Cycle.
The machine learning life cycle is the cyclical process that data science projects should follow. It defines each step that an organization should follow to take advantage of Machine Learning and Artificial Intelligence (AI) to derive practical business value.
Machine learning life cycle can be divided into 8 steps:
- Define the problem
- Gather Data
- Prepare data
- Choosing a model
- Training
- Prediction
- Interpret and Communicate
- Deployment and Re-Training
Example to follow through
Before going through the steps involved in Machine Learning Life Cycle let’s establish an example to follow throughout this series of blogs.
Let’s say you work for a data science team in a bank. The management requires your team to automate the process of profiling potential customers for loan defaults.
For those of you who don’t understand what “loan default” means, here’s a definition from Investopedia :
Default is the failure to repay a debt including interest or principal on a loan or security. A default can occur when a borrower is unable to make timely payments, misses payments, or avoids or stops making payments. Individuals, businesses, and even countries can fall prey to default if they cannot keep up their debt obligations.
In India we have seen a few individuals fleeing from country after major loan defaults and then completely denying it.
So, this is a major risk factor for financial institutions. Let’s see how we can take this problem and solve it using data and in turn prove to be a value proposition for the company/institution.
Define the problem
First off we need to be absolutely certain about what we want to do. By that I mean it should be clear what we want to do, like do we want to improve an existing process or automate a tedious manual process or implement a new feature for an application, etc.
At this step the data science team might want to sit down with the SMEs to understand the problem and it’s potential impact. The better we understand the problem the better we will be able to make suggestions and ask relevant questions.
In the example that we have taken we have already defined the problem well to start working on it.
So, the problem at hand for our team is:
Profile potential customers for Loan Default. The prediction for profiling will be a binary class classification: Will default(1) or Will not default(0).
Gather Data
In this step we find data sources relevant to our problem statement. How do we identify if data is relevant or not? Well, this is where the questions you asked while defining the problem come in handy.
Let’s ask ourselves, for our problem what data could be relevant?
We can come up with arguments like:
- Historical data of loans of the customer with our bank or some other bank(different system).
- Pending loans(may or may not be different system).
- Current credit score(flat file via a report).
- Assets of the customer(internal database via an online form filled by user).
- Income per annum(internal database via an online form filled by user), etc
Here we have identified a few data sources, as mentioned these could belong to our internal system or to other systems.
The data that we collect could come from various sources such as:
- Flat file sources
- Different databases
- Different systems via APIs, etc.
After identifying the data sources we will create pipelines to collect data from various sources and integrate them to our system.
This step includes the following tasks:
- Identify data source
- Collect data
- Integrate data to our system
Prepare data
This is the first step where we take an actual peek into the data and write some code. In this step we try to find insights from our data and check the relevance of data for our problem. We have two major steps of Data Science involved here:
- Data Pre-Processing: This is one of the most important steps in the Machine Learning Life Cycle. Real world data doesn’t usually come in an understandable format. So, in this step we:
- Clean the data
- Transform the data
- Reduce the data
We pre-process the data to maintain data quality so that when we analyse the data to answer business questions and choose model to train we don’t find misleading results.
- Exploratory Data Analysis(EDA): After we’re done with pre-processing of data, the data is ready to be analyzed. During EDA we try to find useful insights from the data like:
- Spread of data using PDF & CDF plots.
- Correlation between features using correlation matrix/heat map of correlation matrix.
- Central tendencies of features
- Choose performance metric, etc.
During EDA we also try to answer questions like for our example people with what range of income tend to be loan defaulters?
We also try to prove hypothesis like people with >5 pending loans tend to be defaulters.
During EDA we tend to explore the data to its depth and find as many useful insights as possible. These two processes are usually the most time consuming processes in a Machine Learning Life Cycle process.
Data pre-processing and EDA are one of the most important and time consuming steps in Machine Learning Life Cycle.
These are very big topics in themselves and deserve blogs of their own. Hence I will write blogs explaining both the processes in detail.
Choosing a model
Once we have cleaned our data and found trends in data we decide which model to choose for our problem. In our example we have a classification problem, hence we will choose a classification algorithm.
The other question that needs to be asked here is:
Should we go with Machine Learning or Deep Learning?
- If the size of dataset is not massive(~ 1 million rows) then we can use Machine Learning algorithms otherwise we should look into Deep Learning. This image shows a general trend of performance of DL vs ML models with increase in data:
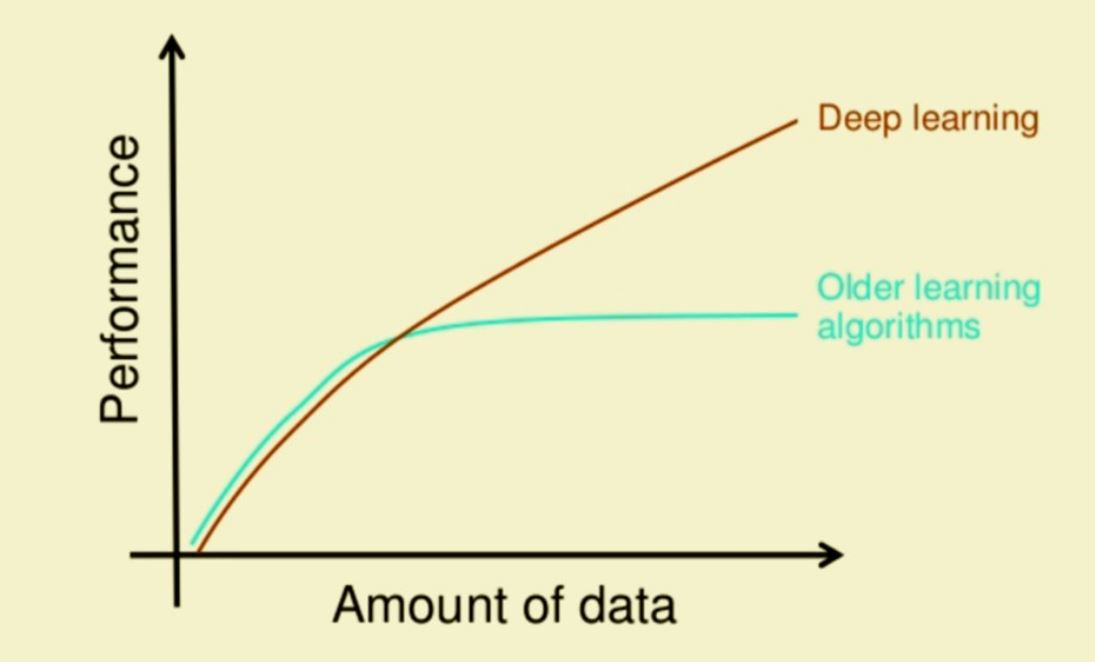
- Deep Learning solutions usually require high end infrastructure which costs more.
For our problem we can train different base classification models such as:
- Logistic Regression
- Decision Trees
- Random Forest
- XGBoost
and check which algorithm performs better.
We will choose which ever model out of the trained models give the best value for chosen performance metric.
This step is also pretty big hence will get a standalone blog.
Training
The next step is to train the chosen model and tune the hyper-parameters to get the best fit model, that neither underfits nor overfits. That is, a generalized model with a healthy test score.
Training a model consists of following tasks:
- Hyper-parameter tuning
- Cross validation
- Evaluation
Based on whatever model we choose the hyper-parameters change, we use techniques like:
- K-Fold cross validation
- Stratified K-Fold cross validation for imbalanced datasets
- LOOCV -Leave one out cross-validation
to evaluate the model on an array of hyper-parameters and check which combination of hyper-parameters give the best value of performance metric.
Based on the cross validation score we can check which combination of hyper-parameters give the best value of performance metric. Using these hyper-parameters we train our final model on all of training data.
Prediction
Having trained a final model we save this model to a binary file so we can refer the model whenever we want to get predictions from it.
We usually write APIs to communicate with the model. Also, in this step we check the inference time of model which is very important in case of internet applications.
In this step we write APIs for communicating with the model and also check the inference time of model.
Interpret and Communicate
This is a crucial step when working in an organization. The model that we have trained should be interpretable and not be a black-box. We should be able to explain why and how the model is predicting to people who don’t understand the specifics of data science. Hence we should try to train the simplest possible model.
Visualization of model performance, features importance, inference time, etc. help a lot in communicating the results to business users.
In this step we communicate to management/business users how good our model performs and what would be the impact of wrong predictions on day to day business.
Deployment and Re-Training
Models along with their communication API need to be deployed to a server or cloud environment, whichever the organization uses. As of current industry trend cloud environments are the most trending deployment environments.
Most used deployment environment for Machine Learning models are:
There are also several factors to consider while deploying the model, such as:
- Frequency of predictions required.
- Latency of predictions and SLA.
- Operational cost for the required infrastructure, etc.
As the time passes we collect more and more data which we can further use to train our model and get better predictions. The frequency at which we need to retrain our model depends on the domain and the problem we are solving.
Deployment and Re-training are the final steps in a Machine Learning Life Cycle process. Now our model is being fed with real world data and is producing results based on all the above steps we understood.
Closing words
In this blog I have not been able to describe everything in depth. So, for each Machine Learning Life Cycle step I will write a blog describing it in detail.
Hope you liked the blog!
Keep an eye out for upcoming blogs.
If you liked the blog it would be great if you could share it with others.